| Binary | ASCII | Decimal | Hexadecimal | Octal |
|---|---|---|---|---|
| 0000000 | null | 0 | 0 | 0 |
| 0000001 | start of header | 1 | 1 | 1 |
| 0000010 | start of text | 2 | 2 | 2 |
| 0000011 | end of text | 3 | 3 | 3 |
| 0000100 | end of transmission | 4 | 4 | 4 |
| 0000101 | enquire | 5 | 5 | 5 |
| 0000110 | acknowledge | 6 | 6 | 6 |
| 0000111 | bell | 7 | 7 | 7 |
| 0001000 | backspace | 8 | 8 | 10 |
| 0001001 | horizontal tab | 9 | 9 | 11 |
| 0001010 | linefeed | 10 | A | 12 |
| 0001011 | vertical tab | 11 | B | 13 |
| 0001100 | form feed | 12 | C | 14 |
| 0001101 | carriage return | 13 | D | 15 |
| 0001110 | shift out | 14 | E | 16 |
| 0001111 | shift in | 15 | F | 17 |
| 0010000 | data link escape | 16 | 10 | 20 |
| 0010001 | device control 1/Xon | 17 | 11 | 21 |
| 0010010 | device control 2 | 18 | 12 | 22 |
| 0010011 | device control 3/Xoff | 19 | 13 | 23 |
| 0010100 | device control 4 | 20 | 14 | 24 |
| 0010101 | negative acknowledge | 21 | 15 | 25 |
| 0010110 | synchronous idle | 22 | 16 | 26 |
| 0010111 | end of transmission block | 23 | 17 | 27 |
| 0011000 | cancel | 24 | 18 | 30 |
| 0011001 | end of medium | 25 | 19 | 31 |
| 0011010 | end of file/ substitute | 26 | 1A | 32 |
| 0011011 | escape | 27 | 1B | 33 |
| 0011100 | file separator | 28 | 1C | 34 |
| 0011101 | group separator | 29 | 1D | 35 |
| 0011110 | record separator | 30 | 1E | 36 |
| 0011111 | unit separator | 31 | 1F | 37 |
| 001e+05 | space | 32 | 20 | 40 |
| 0100001 | ! | 33 | 21 | 41 |
| 0100010 | " | 34 | 22 | 42 |
| 0100011 | # | 35 | 23 | 43 |
| 0100100 | $ | 36 | 24 | 44 |
| 0100101 | % | 37 | 25 | 45 |
| 0100110 | & | 38 | 26 | 46 |
| 0100111 | ' | 39 | 27 | 47 |
| 0101000 | ( | 40 | 28 | 50 |
| 0101001 | ) | 41 | 29 | 51 |
| 0101010 | * | 42 | 2A | 52 |
| 0101011 | + | 43 | 2B | 53 |
| 0101100 | , | 44 | 2C | 54 |
| 0101101 | - | 45 | 2D | 55 |
| 0101110 | . | 46 | 2E | 56 |
| 0101111 | / | 47 | 2F | 57 |
| 0110000 | 0 | 48 | 30 | 60 |
| 0110001 | 1 | 49 | 31 | 61 |
| 0110010 | 2 | 50 | 32 | 62 |
| 0110011 | 3 | 51 | 33 | 63 |
| 0110100 | 4 | 52 | 34 | 64 |
| 0110101 | 5 | 53 | 35 | 65 |
| 0110110 | 6 | 54 | 36 | 66 |
| 0110111 | 7 | 55 | 37 | 67 |
| 0111000 | 8 | 56 | 38 | 70 |
| 0111001 | 9 | 57 | 39 | 71 |
| 0111010 | : | 58 | 3A | 72 |
| 0111011 | ; | 59 | 3B | 73 |
| 0111100 | < | 60 | 3C | 74 |
| 0111101 | = | 61 | 3D | 75 |
| 0111110 | > | 62 | 3E | 76 |
| 0111111 | ? | 63 | 3F | 77 |
| 001e+06 | @ | 64 | 40 | 100 |
| 1000001 | A | 65 | 41 | 101 |
| 1000010 | B | 66 | 42 | 102 |
| 1000011 | C | 67 | 43 | 103 |
| 1000100 | D | 68 | 44 | 104 |
| 1000101 | E | 69 | 45 | 105 |
| 1000110 | F | 70 | 46 | 106 |
| 1000111 | G | 71 | 47 | 107 |
| 1001000 | H | 72 | 48 | 110 |
| 1001001 | I | 73 | 49 | 111 |
| 1001010 | J | 74 | 4A | 112 |
| 1001011 | K | 75 | 4B | 113 |
| 1001100 | L | 76 | 4C | 114 |
| 1001101 | M | 77 | 4D | 115 |
| 1001110 | N | 78 | 4E | 116 |
| 1001111 | O | 79 | 4F | 117 |
| 1010000 | P | 80 | 50 | 120 |
| 1010001 | Q | 81 | 51 | 121 |
| 1010010 | R | 82 | 52 | 122 |
| 1010011 | S | 83 | 53 | 123 |
| 1010100 | T | 84 | 54 | 124 |
| 1010101 | U | 85 | 55 | 125 |
| 1010110 | V | 86 | 56 | 126 |
| 1010111 | W | 87 | 57 | 127 |
| 1011000 | X | 88 | 58 | 130 |
| 1011001 | Y | 89 | 59 | 131 |
| 1011010 | Z | 90 | 5A | 132 |
| 1011011 | [ | 91 | 5B | 133 |
| 1011100 | \ | 92 | 5C | 134 |
| 1011101 | ] | 93 | 5D | 135 |
| 1011110 | ^ | 94 | 5E | 136 |
| 1011111 | _ | 95 | 5F | 137 |
| 1100000 | ` | 96 | 60 | 140 |
| 1100001 | a | 97 | 61 | 141 |
| 1100010 | b | 98 | 62 | 142 |
| 1100011 | c | 99 | 63 | 143 |
| 1100100 | d | 100 | 64 | 144 |
| 1100101 | e | 101 | 65 | 145 |
| 1100110 | f | 102 | 66 | 146 |
| 1100111 | g | 103 | 67 | 147 |
| 1101000 | h | 104 | 68 | 150 |
| 1101001 | i | 105 | 69 | 151 |
| 1101010 | j | 106 | 6A | 152 |
| 1101011 | k | 107 | 6B | 153 |
| 1101100 | l | 108 | 6C | 154 |
| 1101101 | m | 109 | 6D | 155 |
| 1101110 | n | 110 | 6E | 156 |
| 1101111 | o | 111 | 6F | 157 |
| 1110000 | p | 112 | 70 | 160 |
| 1110001 | q | 113 | 71 | 161 |
| 1110010 | r | 114 | 72 | 162 |
| 1110011 | s | 115 | 73 | 163 |
| 1110100 | t | 116 | 74 | 164 |
| 1110101 | u | 117 | 75 | 165 |
| 1110110 | v | 118 | 76 | 166 |
| 1110111 | w | 119 | 77 | 167 |
| 1111000 | x | 120 | 78 | 170 |
| 1111001 | y | 121 | 79 | 171 |
| 1111010 | z | 122 | 7A | 172 |
| 1111011 | { | 123 | 7B | 173 |
| 1111100 | | | 124 | 7C | 174 |
| 1111101 | } | 125 | 7D | 175 |
| 1111110 | ~ | 126 | 7E | 176 |
| 1111111 | DEL | 127 | 7F | 177 |
Files & the File System
Modern Plain Text Computing
Week 01b
October 7, 2024
What is a file?
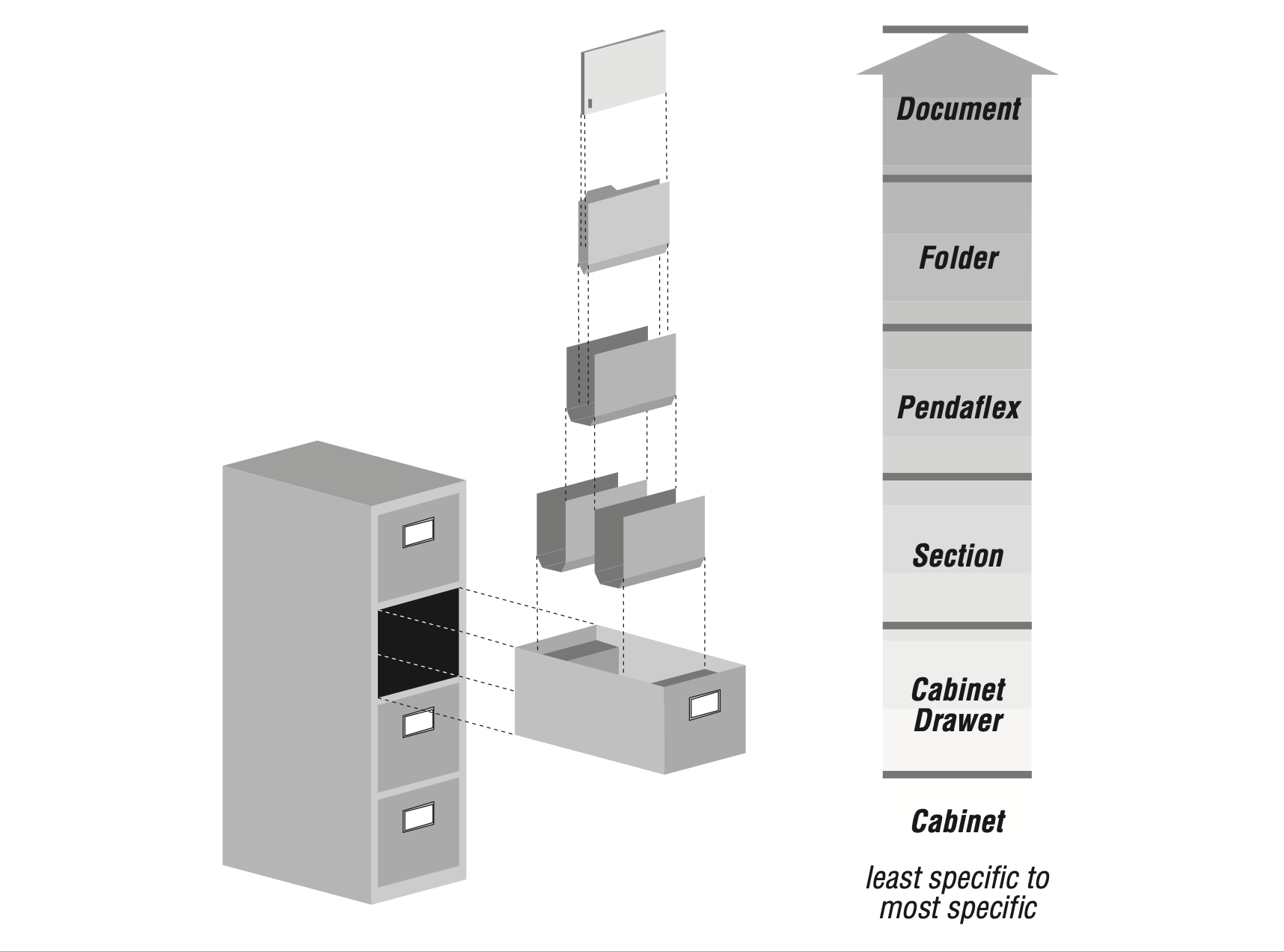
You very likely have never used one of these. Perhaps you’ve never even seen one in real life.
The file cabinet!

“Could capitalism, surveillance, and governance have developed in the twentieth century without filing cabinets? Of course, but only if there had been another way to store and circulate paper efficiently; if that had been the case, that technology would be the object of this book.” — Craig Robertson The Filing Cabinet: A Vertical History of Information (University of Minnesota Press, 2021), 3.
The file cabinet!

“Cabinet logic involves the creation of interior compartments to organize storage space according to classification and indexing systems … Partitions made from paper, not wood, divided storage space to create rigorous order; these partitions took the form of tabbed manila folders separated by tabbed guide cards. This iteration of the logic dispensed with a separate index to make paper discoverable by utilizing the “very organization of the material and its location” with the “vertical guides serving as locating medium.” Elimination of an index was signaled in filing literature by the terms “direct alphabet index” and “automatic index” … Without the need to consult a separate index, a clerk grouped papers together on their edge behind tabs labeled with classifications, so any given paper could be found quickly.” — Robertson, The Filing Cabinet, 104–5.
Index cards

Like a filing cabinet, but smol
Index cards

A music box

A Jacquard Loom

Jacquard Loom Cards

Hollerith Cards
Hollerith Machines

Hollerith Machines
Hollerith Machines
Hollerith Operators

Demonstrating a older card-puncher, probably to show how things had improved with census tabulation methods. This is likely the “Before” picture with a roll from the 1890 Census. The card-puncher is a Pantograph.
Hollerith Operators

Same woman as the previous photo; her colleague on the right is demonstrating the newer, faster IBM Type 001 Key Puncher. (Again, probably a re-enactment / demo of earlier techniques.)
Logic from Sand

The best book to read about how the guts of a programmable computer works is Charles Petzold’s Code: The Hidden Language of Computer Hardware and Software, 2nd ed. (Microsoft Press, 2022).
IBM punch cards

In the longer term, punch card writers got much more efficient. And now they could be fed into machines that could use them to run programs instead of just tabulate the punches.
IBM punch cards

An IBM punch card is 80 columns wide. The first CRT terminals displayed 80 columns of text for this reason. You’ll see 80 columns of text pop up as a standard in all kinds of places.
Big Iron

No screens! Paper in, paper out for the operator; magnetic tapes for storage in the background. This is an IBM/360, the most important class of mainframe in the 1960s and early 1970s.
One thing that’s hard to convey in pictures is the way that—because of all the daisy-wheel or tractor-fed printing, mechanical card processing, and huge reels of tape spinning up and down—rooms like this were loud.
Storage

Notice that the “File” here is the machine itself, or at most a single disk platter.
Storage

The older way of speaking is still with us, as when we speak of someone’s “Application File” or “Tenure File”; that is, a file is a collection of related documents.
But the newer way, where “file” means “a single document”, is now dominant, especially in computing.
ASCII
The venerable and now outdated ASCII character set: 26 uppercase letters; 26 lowercase letters; 10 digits; 32 printable symbols; and 33 control characters ultimately derived from telegraph code and teletype machines.

A late-model teletype (TTY) machine

The DEC VT-100 Terminal (1978)

The IBM PC (1981)

The Apple Macintosh (1984)

The macOS Terminal app icon
Files
- Our data is stored — or represented as being stored — in a file system.
- This is, again, a way of organizing items for our benefit.
- The UNIX operating system developed at Bell Labs codifies the modern “file” metaphor.
- Files are named items that live in a hierarchical file system. “Ordinary” documents like
notes.txtare thought of as files, which seems natural to us now. - The hierarchy is made of folders or “directories” that, like a filing cabinet, can nest inside one another and inside larger storage units.
- By navigating the hierarchy from its root, we can trace a path to any particular file.