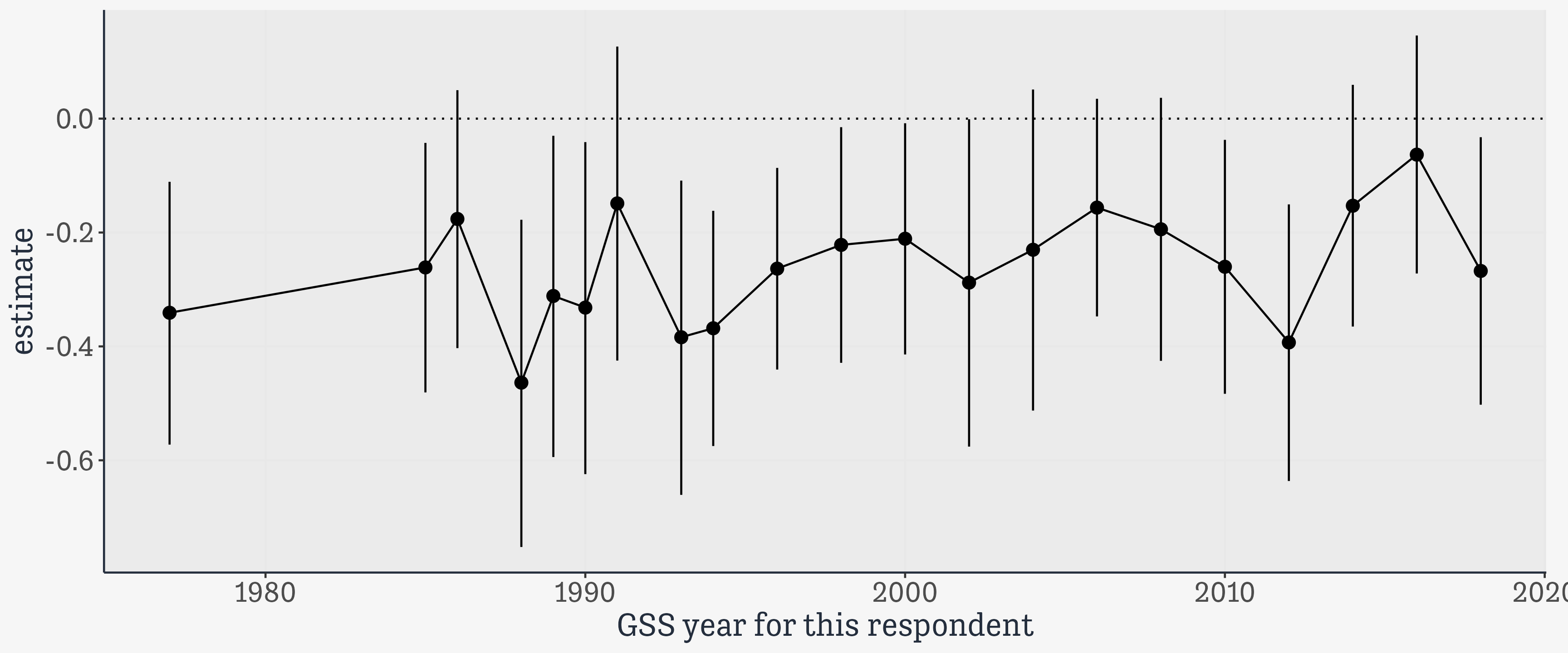
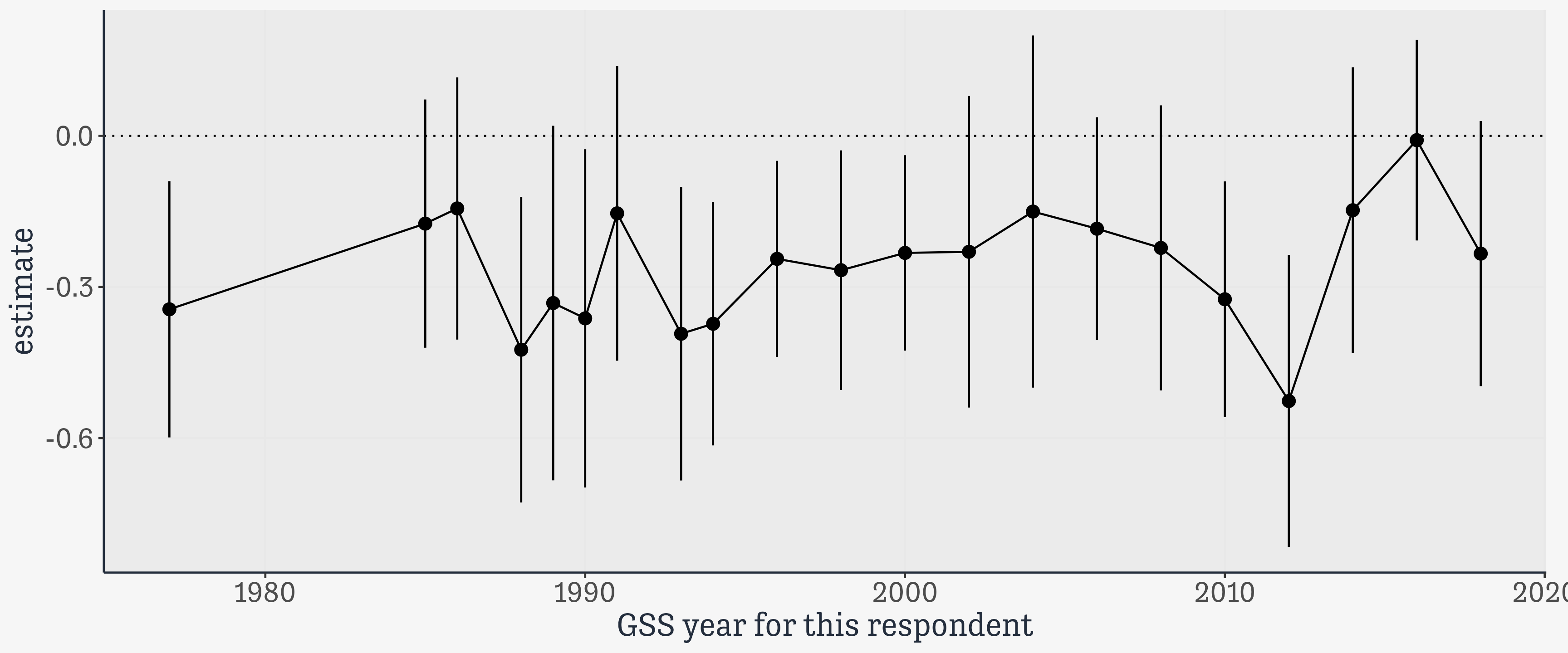
# A tibble: 75,699 × 6,867
year id wrkstat hrs1 hrs2 evwork occ prestige
<dbl+lbl> <dbl> <dbl+lbl> <dbl+lbl> <dbl+lbl> <dbl+lbl> <dbl> <dbl+lb>
1 1972 1 1 [workin… NA(i) [iap] NA(i) [iap] NA(i) [iap] 205 50
2 1972 2 5 [retire… NA(i) [iap] NA(i) [iap] 1 [yes] 441 45
3 1972 3 2 [workin… NA(i) [iap] NA(i) [iap] NA(i) [iap] 270 44
4 1972 4 1 [workin… NA(i) [iap] NA(i) [iap] NA(i) [iap] 1 57
5 1972 5 7 [keepin… NA(i) [iap] NA(i) [iap] 1 [yes] 385 40
6 1972 6 1 [workin… NA(i) [iap] NA(i) [iap] NA(i) [iap] 281 49
7 1972 7 1 [workin… NA(i) [iap] NA(i) [iap] NA(i) [iap] 522 41
8 1972 8 1 [workin… NA(i) [iap] NA(i) [iap] NA(i) [iap] 314 36
9 1972 9 2 [workin… NA(i) [iap] NA(i) [iap] NA(i) [iap] 912 26
10 1972 10 1 [workin… NA(i) [iap] NA(i) [iap] NA(i) [iap] 984 18
# ℹ 75,689 more rows
# ℹ 6,859 more variables: wrkslf <dbl+lbl>, wrkgovt <dbl+lbl>,
# commute <dbl+lbl>, industry <dbl+lbl>, occ80 <dbl+lbl>, prestg80 <dbl+lbl>,
# indus80 <dbl+lbl>, indus07 <dbl+lbl>, occonet <dbl+lbl>, found <dbl+lbl>,
# occ10 <dbl+lbl>, occindv <dbl+lbl>, occstatus <dbl+lbl>, occtag <dbl+lbl>,
# prestg10 <dbl+lbl>, prestg105plus <dbl+lbl>, indus10 <dbl+lbl>,
# indstatus <dbl+lbl>, indtag <dbl+lbl>, marital <dbl+lbl>, …